
GRAB: A Dataset of Whole-Body Human Grasping of Objects
Omid Taheri, Nima Ghorbani, Michael J. Black, Dimitrios Tzionas
To appear in Proceedings European Conference on Computer Vision (ECCV), 2020.
[PDF] [Code] [YouTube] [Project Page] [Bibtex]
Abstract
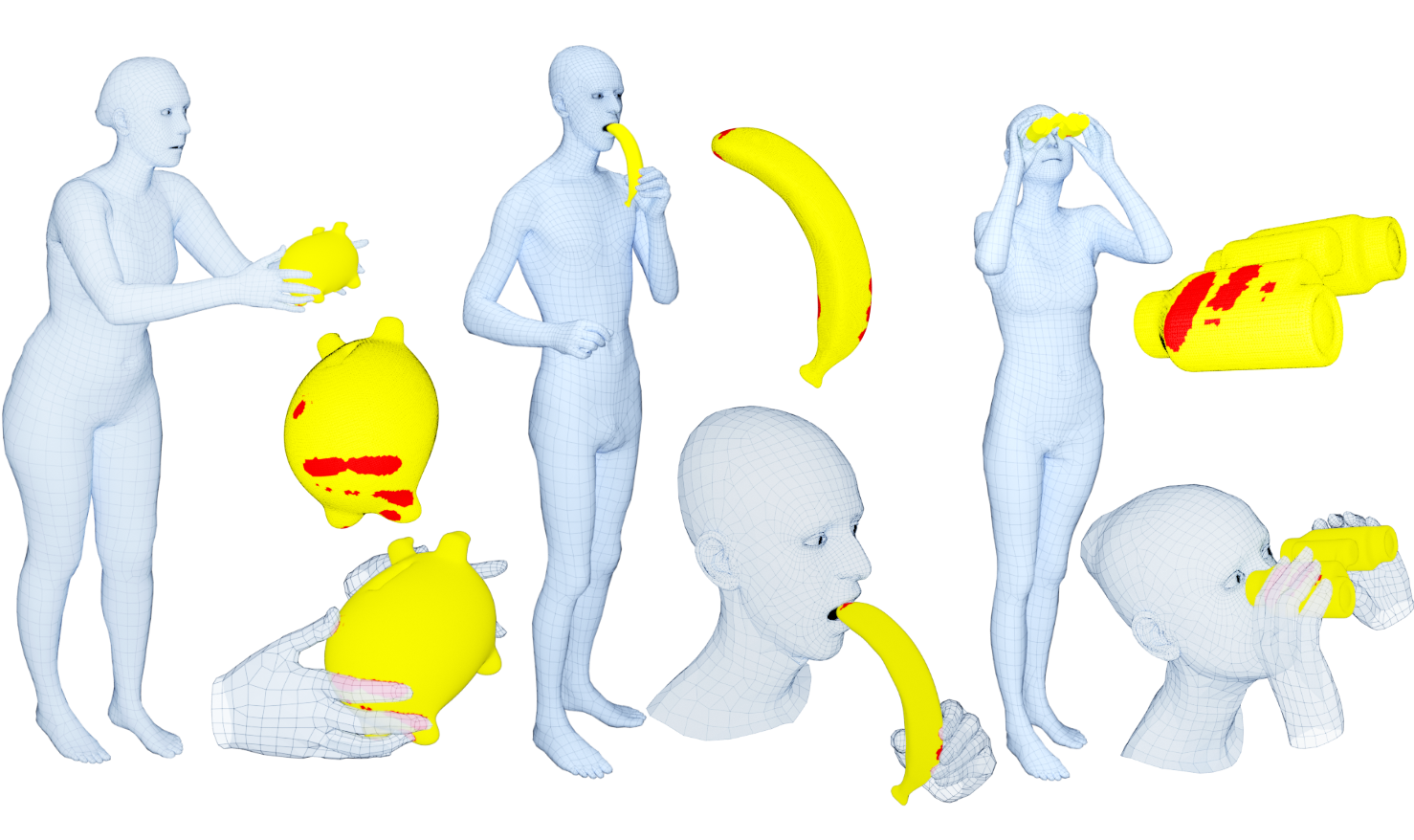
Training computers to understand, model, and synthesize human grasping requires a rich dataset containing complex 3D object shapes, detailed contact information, hand pose and shape, and the 3D body motion over time. While “grasping” is commonly thought of as a single hand stably lifting an object, we capture the motion of the entire body and adopt the generalized notion of “whole-body grasps”. Thus, we collect a new dataset, called GRAB (GRasping Actions with Bodies), of whole-body grasps, containing full 3D shape and pose sequences of 10 subjects interacting with 51 everyday objects of varying shape and size. Given MoCap markers, we fit the full 3D body shape and pose, including the articulated face and hands, as well as the 3D object pose. This gives detailed 3D meshes over time, from which we compute contact between the body and object. This is a unique dataset, that goes well beyond existing ones for modeling and understanding how humans grasp and manipulate objects, how their full body is involved, and how interaction varies with the task. We illustrate the practical value of GRAB with an example application; we train GrabNet, a conditional generative network, to predict 3D hand grasps for unseen 3D object shapes. The dataset and code are available for research purposes at https://grab.is.tue.mpg.de.